Identifying Fraudulent Activities
Happy New Year
Happy 2019. In 2019, to be the one who I want to be.
Project Description
Company XYZ is an e-commerce site that sells hand-made clothes. You have to build a model that predicts whether a user has a high probability of using the site to perform some illegal activity or not.
The procedure of this project invovles:
- merge two datasets to transform its ip address to corresponding.
- feature engineering to find out features related to fraud activities
- Build a model to predict whether an activity is fraudulent or not.
- Explain how different assumptions about the cost of false positives vs false negatives would impact the model.
- How would you explain your boss how the model is making the predictions? What kinds of users are more likely to be classified as at risk? What are their characteristics?
- Let’s say you now have this model which can be used live to predict in real time if an activity is fraudulent or not. From a product perspective, how would you use it? That is, what kind of different user experiences would you build based on the model output?
**From data science take home challenges **
Import datasets
import pandas as pd
pd.options.display.float_format = '{:.0f}'.format
transactions = pd.read_csv("Fraud/Fraud_Data.csv",parse_dates=True)
ip = pd.read_csv("Fraud/IpAddress_to_Country.csv")
transactions.head()
| user_id | signup_time | purchase_time | purchase_value | device_id | source | browser | sex | age | ip_address | class | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22058 | 2015-02-24 22:55:49 | 2015-04-18 02:47:11 | 34 | QVPSPJUOCKZAR | SEO | Chrome | M | 39 | 732758369 | 0 |
| 1 | 333320 | 2015-06-07 20:39:50 | 2015-06-08 01:38:54 | 16 | EOGFQPIZPYXFZ | Ads | Chrome | F | 53 | 350311388 | 0 |
| 2 | 1359 | 2015-01-01 18:52:44 | 2015-01-01 18:52:45 | 15 | YSSKYOSJHPPLJ | SEO | Opera | M | 53 | 2621473820 | 1 |
| 3 | 150084 | 2015-04-28 21:13:25 | 2015-05-04 13:54:50 | 44 | ATGTXKYKUDUQN | SEO | Safari | M | 41 | 3840542444 | 0 |
| 4 | 221365 | 2015-07-21 07:09:52 | 2015-09-09 18:40:53 | 39 | NAUITBZFJKHWW | Ads | Safari | M | 45 | 415583117 | 0 |
ip.head()
| lower_bound_ip_address | upper_bound_ip_address | country | |
|---|---|---|---|
| 0 | 16777216 | 16777471 | Australia |
| 1 | 16777472 | 16777727 | China |
| 2 | 16777728 | 16778239 | China |
| 3 | 16778240 | 16779263 | Australia |
| 4 | 16779264 | 16781311 | China |
Assign country according to their ip address
Firstly, I tried iterate all the rows in the ip dataframe. However, it took a lot of time.
Considering the dataset is sorted by lower bound and upper bound. Binary search can be applied here.
It turned out to be quicker and more efficient.
def setCountry(x):
"""
for index, row in ip.iterrows():
if row['lower_bound_ip_address']<x and row['upper_bound_ip_address']>x:
return row['country']
return "Unknown"
"""
## the method above is too slow. We change to binary search
low = 0
high = 138845
while low<=high:
mid = low+(high-low)//2
if ip.loc[mid,'lower_bound_ip_address']<=x and ip.loc[mid,'upper_bound_ip_address']>=x:
return ip.loc[mid,'country']
if ip.loc[mid,'lower_bound_ip_address']>x:
high = mid-1
elif ip.loc[mid,"upper_bound_ip_address"]<x:
low = mid+1
return "Unknown"
transactions["Country"] = transactions.ip_address.apply(setCountry)
Some ip address can not find its country.
transactions.Country.value_counts().head()
United States 58049
Unknown 21966
China 12038
Japan 7306
United Kingdom 4490
Name: Country, dtype: int64
Feature engineering
transactions have the current features. We need to dig more information from it.
First, let’s check if user id is unique.
Check if the user id is unique
len(transactions.user_id)==len(transactions.user_id.unique())
True
Check if the device id is unique
Users can share the same device and they can be suspicious.
len(transactions.device_id)==len(transactions.device_id.unique())
False
Check if the ip address is unique
Similarly, ip addresses can be the same for users if they try to fake.
len(transactions.ip_address)==len(transactions.ip_address.unique())
False
Sharing info
One device id can appear multiple times. This could be suspicious.
transactions['device_sharing']=transactions.groupby('device_id').user_id.transform('count')
transactions['ip_sharing']=transactions.groupby('ip_address').user_id.transform('count')
sharing ip and sharing device
It turns out if two device is the same and their ip address it more likedly to be the same as well. But it is not always the case. Therefore, we would keep two features.
(transactions['ip_sharing']==transactions['device_sharing']).value_counts()
True 139583
False 11529
dtype: int64
Encode country
I tried two methods.
-
First, encode country into frequent ones and rare one. For example, most of users are from US, China and Japan. We would record their nations while for others just label “rare”.
-
Second, just encode country into Known and Unknown.
It turns out two methods did not make big differences. To simply, we select the second method to represent the country.
def encodeCountry(x):
if x in ['United States', 'Unknown', 'China', 'Japan', 'United Kingdom',
'Korea Republic of', 'Germany', 'France', 'Canada', 'Brazil', 'Italy',
'Australia', 'Russian Federation']:
return x
else:
return "Rare"
def encodeCountry1(x):
if x=="Unknown":
return 0
else:
return 1
transactions['ipvalid']=transactions.Country.apply(encodeCountry1)
Dig dates
We are also given when the user signed up and when the user purchased. It is understandable the period between the sign up and purchase time matters. Also, when the user signed up and when the user purchased can be important as well. We extracted days, months, and hour from its date.
transactions['purchase_day']=pd.to_datetime(transactions.purchase_time).dt.dayofweek
transactions['purchase_hour']=pd.to_datetime(transactions.purchase_time).dt.hour
transactions['purchase_month']=pd.to_datetime(transactions.purchase_time).dt.month
transactions['signup_day']=pd.to_datetime(transactions.signup_time).dt.dayofweek
transactions['signup_hour']=pd.to_datetime(transactions.signup_time).dt.hour
transactions['signup_month']=pd.to_datetime(transactions.signup_time).dt.month
transactions['length'] = pd.to_datetime(pd.to_datetime(transactions.signup_time)-pd.to_datetime(transactions.purchase_time)).dt.day
transactions.ipvalid.value_counts()
1 129146
0 21966
Name: ipvalid, dtype: int64
users = transactions.drop(["user_id","device_id","ip_address","Country","signup_time","purchase_time"],axis=1)
users.head()
| purchase_value | source | browser | sex | age | class | ipvalid | purchase_day | purchase_hour | purchase_month | signup_day | signup_hour | signup_month | length | device_sharing | ip_sharing | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 34 | SEO | Chrome | M | 39 | 0 | 1 | 5 | 2 | 4 | 1 | 22 | 2 | 9 | 1 | 1 |
| 1 | 16 | Ads | Chrome | F | 53 | 0 | 1 | 0 | 1 | 6 | 6 | 20 | 6 | 31 | 1 | 1 |
| 2 | 15 | SEO | Opera | M | 53 | 1 | 1 | 3 | 18 | 1 | 3 | 18 | 1 | 31 | 12 | 12 |
| 3 | 44 | SEO | Safari | M | 41 | 0 | 0 | 0 | 13 | 5 | 1 | 21 | 4 | 26 | 1 | 1 |
| 4 | 39 | Ads | Safari | M | 45 | 0 | 1 | 2 | 18 | 9 | 1 | 7 | 7 | 11 | 1 | 1 |
Model
It is time to build a model to predict a fraud. First, we need split training and test.
Train test split and conversion
from sklearn.model_selection import train_test_split
X = users.drop(["class"],axis=1)
X = pd.get_dummies(X,drop_first=True)
y = users["class"]
X_train, X_test, y_train, y_test = train_test_split(X,y,stratify=y,test_size=0.3,random_state=42)
X.shape
(151112, 19)
Find the best model and best parameters
Here, we tried several classification models and found random forest classifier works well.
In this case, since it is a highly imbalanced dataset. We used AUC metric to evaluate a model. AUC is a great metric for this type problem. Also, AUC gives the general performance for all the thresholds. Last, we care about the balanced between false negatives and false positives, so AUC would be fit.
The baseline model can give 90.66% accuracy
100-transactions['class'].mean()*100
90.635422732807456
GridSearchCV
Grid serach cv makes our life easier. However, it can take longer time. Thus, I firstly used train and test to test each models and narrowed down to random forest classifier.
from sklearn.model_selection import GridSearchCV
param_grid = {
'max_depth':[40,50,60],
'max_features':[4,8,13,19],
#"min_samples_leaf":[3,4,5],
#"min_samples_split":[8,10,12],
"n_estimators":[10]
}
model = RandomForestClassifier(min_samples_leaf=1,criterion='gini')
grid_search_model = GridSearchCV(estimator=model,param_grid=param_grid,cv=5,scoring="roc_auc")
grid_search_model.fit(X_train,y_train)
grid_search_model.best_params_
{'max_depth': 60, 'max_features': 4, 'n_estimators': 10}
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
#model = LogisticRegression(class_weight="balanced")
model = RandomForestClassifier(class_weight={1:1,0:1},n_estimators=10,
max_features=4,max_depth=60,min_samples_leaf=1,criterion='gini')
#good,min_samples_split=0.15
#model = GaussianNB()
#model = KNeighborsClassifier(2) #good
#model = DecisionTreeClassifier(max_depth=12,max_features=5) #good #class_weight={1:1.5,0:1}
#model = SVC(kernel="linear", C=0.025)
#model = SVC(gamma=2, C=1) # too slow
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
from sklearn.metrics import classification_report
print(classification_report(y_test,y_pred))
precision recall f1-score support
0 0.95 1.00 0.98 41089
1 0.96 0.54 0.69 4245
avg / total 0.96 0.95 0.95 45334
Model Evaluation
In general, the model gives 96% accuracy greater than the baseline one. Thus, it performs well.
Then, for each class, the precision high. It indicates that if we predicts a class, the predicted can be really true. In other words, if we tell an activity is suspicious, it is higly real. However, the recall for class 1 is 0.54, suggesting we can only find half of true fraud activities.
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
y_pred_proba = model.predict_proba(X_test)[::,1]
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
auc = roc_auc_score(y_test, y_pred_proba)
plt.plot(fpr,tpr,label="auc="+str(auc))
plt.legend(loc='best')
<matplotlib.legend.Legend at 0x213893c1710>
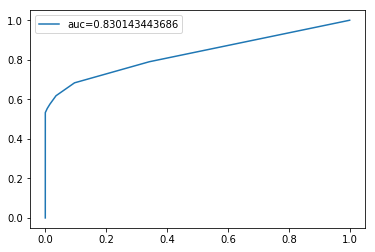
AUC=0.83. The model is good.
The threshold now is 0.5.
We can treak the threshold based on assumptions on trade-off between true positives and false positives.
False positives happen when the activity is valid but predicted fraud. If the cost of false positives is higher, we may lose a lot potential buyers because we close the valid transaction. In this case, we maybe conservative. Thus, we increase the cut-off, the threshold. Thus, buyers are harder to be predicted as fraud.
False negatives happen when the activity is fraud but not detected. If the cost of false negatives is higher, we may have a loss since the transaction is fraud. In this case, we maybe aggressive to find more fraud activities. Thus, we decrease the cut-off, the threshold. Thus, buyers are easier to be predicted as fraud.
Feature Importance
X.columns
Index(['purchase_value', 'age', 'device_sharing', 'purchase_day',
'purchase_hour', 'purchase_month', 'signup_day', 'signup_hour',
'signup_month', 'length', 'ipvalid', 'ip_sharing', 'source_Direct',
'source_SEO', 'browser_FireFox', 'browser_IE', 'browser_Opera',
'browser_Safari', 'sex_M'],
dtype='object')
pd.options.display.float_format = '{:.3f}'.format
pd.Series(model.feature_importances_,index=X.columns).sort_values(ascending=False)
device_sharing 0.222
ip_sharing 0.173
length 0.158
purchase_value 0.067
age 0.053
purchase_month 0.052
signup_month 0.051
purchase_hour 0.050
signup_hour 0.050
signup_day 0.035
purchase_day 0.032
sex_M 0.010
browser_IE 0.008
browser_FireFox 0.008
browser_Safari 0.008
source_SEO 0.007
source_Direct 0.007
ipvalid 0.007
browser_Opera 0.003
dtype: float64
device sharing, ip sharing, how long it takes for a user to have a first purchase since sign up, purcahse vlaue, and age is top 5 features in predicting a fraud activity
However, if we want to know the direction, we have to build a single decision tree to take a look.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_features=19,max_depth=3,min_samples_leaf=1,criterion='gini') #good #class_weight={1:1.5,0:1}
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
from sklearn.metrics import classification_report
print(classification_report(y_test,y_pred))
precision recall f1-score support
0 0.95 1.00 0.98 41089
1 1.00 0.53 0.70 4245
avg / total 0.96 0.96 0.95 45334
Notice, decision tree classifier can work well.
pd.options.display.float_format = '{:.3f}'.format
pd.Series(model.feature_importances_,index=X.columns).sort_values(ascending=False)
ip_sharing 0.850
length 0.089
device_sharing 0.055
source_Direct 0.005
purchase_month 0.001
purchase_hour 0.000
signup_hour 0.000
age 0.000
ipvalid 0.000
purchase_day 0.000
signup_day 0.000
sex_M 0.000
signup_month 0.000
browser_Safari 0.000
source_SEO 0.000
browser_FireFox 0.000
browser_IE 0.000
browser_Opera 0.000
purchase_value 0.000
dtype: float64
from sklearn.externals.six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
##export_graphviz(model, out_file=dot_data,
# filled=True, rounded=True,
# special_characters=True)
#graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
#Image(graph.create_png())
with open("fraud_tree.txt", "w") as f:
f = export_graphviz(model, out_file=f,feature_names = X.columns,class_names=['NotFraud','Fraud'])
Visualizing tree with webgraphviz
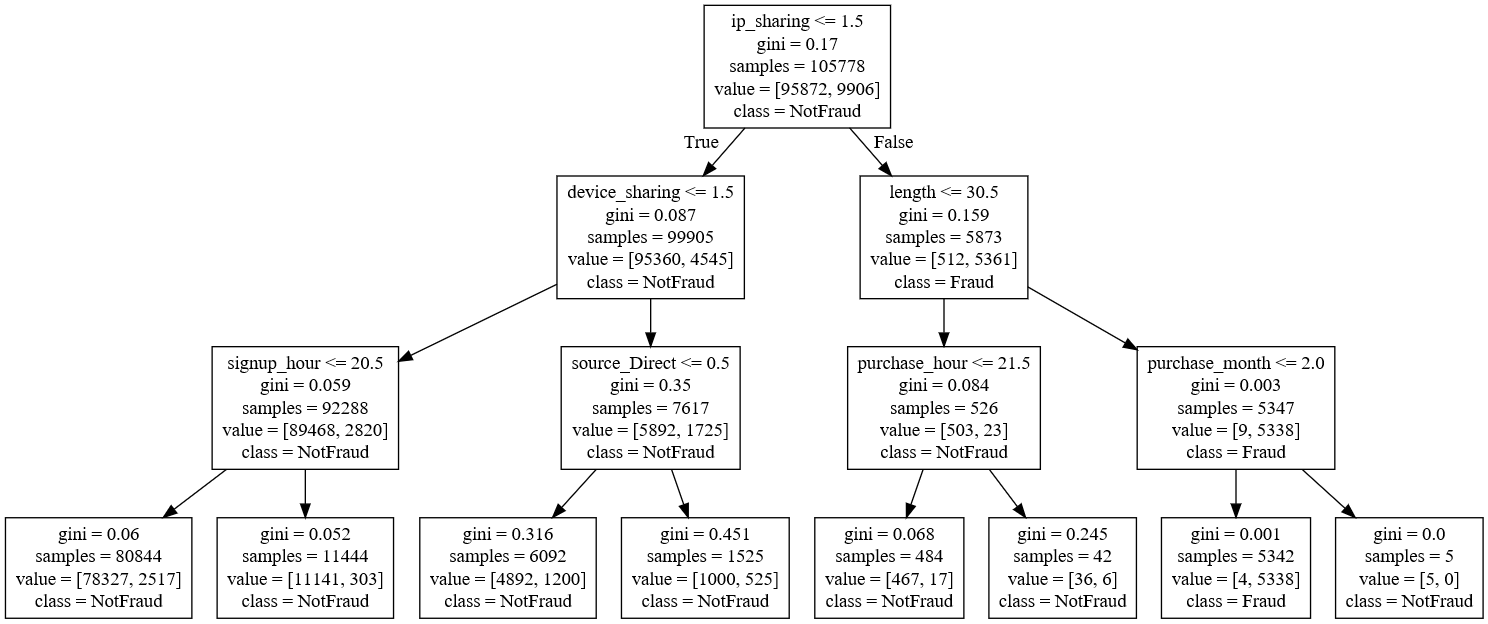
Interpretation
- if an ip address is shared between more than one user and opened less than 30.5 days –>fraud
Shared IP adrress and quick purchase after singing up lead to high probability of fraud.
Product
The final model is randomforest classifier. As the assumption of cost of false negatives and false positives varies, the threshold can be tweaked to meet the requirements. At this point, the model has a 0.5 threshold.
If the cost of false negatives is higher, we need to decrease false negatives. In other words, we need increase the number of positive predictions. To realize it, the threshold need to be decreased.
On the other hand, if the cost of false positives is higher, we need to increase the threshold.
After deciding the threshold, the suspicious transaction should be asked for further authorization.
Review
In this project, we did:
- Binary Search and basic data manipulation
- Classification model built and hyperparameters tuning
- ROC Curve interpretation and trade-off
- Decision Tree built and visualization (not sure why graphviz did not work on Notebook)
- Product sense view
In the future,
- Leanr gradient boosting method
- further learn the relationship with product design
- ROC and Precision-recall trade off this article