Customer Longtime Value in Python
This notebook goes through the calculation in Practical Guide to Calculating Customer Lifetime Value (CLV) with Python. It mainly applies pandas dataframe to deal with the dataset.
Background: Customer Lifetime Value
- It is a prediction of the net profit attributed to the entire future relationship with a customer
- Also defined as the dollar value of a customer relationship based on the projected future cash flows from the customer relationship
- Represents an upper limit on spending to acquire new customers
Step 1. Load the transaction dataset
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4186 entries, 0 to 4185
Data columns (total 4 columns):
TransactionID 4186 non-null int64
TransactionDate 4186 non-null datetime64[ns]
CustomerID 4186 non-null int64
Amount 4186 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(2)
memory usage: 130.9 KB
|
TransactionID |
TransactionDate |
CustomerID |
Amount |
| 0 |
1 |
2012-09-04 |
1 |
20.26 |
| 1 |
2 |
2012-05-15 |
2 |
10.87 |
| 2 |
3 |
2014-05-23 |
2 |
2.21 |
| 3 |
4 |
2014-10-24 |
2 |
10.48 |
| 4 |
5 |
2012-10-13 |
2 |
3.94 |
There are some outliers in the dataset. We need to remove them. The details are not important for this analysis.
#customer_new is the new dataset without outliers
customer_new = customer[(customer.Amount<1000)&(customer.Amount>0)]
Step 2. Determine origin year of customers
|
TransactionID |
TransactionDate |
CustomerID |
Amount |
| 0 |
1 |
2012-09-04 |
1 |
20.26 |
| 1 |
2 |
2012-05-15 |
2 |
10.87 |
| 2 |
3 |
2014-05-23 |
2 |
2.21 |
| 3 |
4 |
2014-10-24 |
2 |
10.48 |
| 4 |
5 |
2012-10-13 |
2 |
3.94 |
We need find each group the customer assigned in. The rule is to record the earliest transaction with each customer
# Get the earliest year each customer have made transactions, stored in group dataframe
group = customer_new.groupby('CustomerID').TransactionDate.unique().apply(min).reset_index()
|
CustomerID |
TransactionDate |
| 0 |
1 |
2012-09-04 |
| 1 |
2 |
2012-05-15 |
| 2 |
3 |
2012-11-26 |
| 3 |
4 |
2015-07-07 |
| 4 |
5 |
2015-01-24 |
# extract years from the dataframe
group['Group'] = group.TransactionDate.dt.year
# Drop date information because we only care the year
group.drop('TransactionDate',axis=1,inplace=True)
|
CustomerID |
Group |
| 0 |
1 |
2012 |
| 1 |
2 |
2012 |
| 2 |
3 |
2012 |
| 3 |
4 |
2015 |
| 4 |
5 |
2015 |
| 5 |
6 |
2013 |
| 6 |
7 |
2012 |
| 7 |
8 |
2012 |
| 8 |
9 |
2010 |
| 9 |
10 |
2010 |
Now, the group dataframe is what we want
Step 3. Calculate cumulative transaction amounts
# Merge customer_new and group so that each custoemr has its group info
transaction = pd.merge(customer_new,
group,
on = 'CustomerID')
# extract year of each transation
transaction['year'] = transaction.TransactionDate.dt.year
# pre is a dataframe grouped by group and year(transaction) and each transaction age
pre=transaction.groupby(['Group','year']).Amount.sum().groupby(level=[0]).cumsum().reset_index()
pre['Origin']=12*(pre['year']-pre['Group']+1)
#Amount_cmltv=pd.DataFrame(transaction.groupby(['Group','year']).Amount.sum().groupby(level=[0]).cumsum().unstack().to_records())
|
Group |
year |
Amount |
Origin |
| 0 |
2010 |
2010 |
2259.67 |
12 |
| 1 |
2010 |
2011 |
3614.78 |
24 |
| 2 |
2010 |
2012 |
5274.81 |
36 |
| 3 |
2010 |
2013 |
6632.37 |
48 |
| 4 |
2010 |
2014 |
7930.69 |
60 |
# Conver the df above to pivot table we want using crosstab function
Amount_cmltv=pd.crosstab(pre.Group,pre.Origin,values=pre.Amount,aggfunc=lambda x:x)
# set the index as we want
Amount_cmltv.index=['2010-01-01 - 2010-12-31',
'2011-01-01 - 2011-12-31',
'2012-01-01 - 2012-12-31',
'2013-01-01 - 2013-12-31',
'2014-01-01 - 2014-12-31',
'2015-01-01 - 2015-12-31',]
#Amount_cmltv.columns = ['Origin', '12','24','36','48','60','72']
| Origin |
12 |
24 |
36 |
48 |
60 |
72 |
| 2010-01-01 - 2010-12-31 |
2259.67 |
3614.78 |
5274.81 |
6632.37 |
7930.69 |
8964.49 |
| 2011-01-01 - 2011-12-31 |
2238.46 |
3757.90 |
5465.99 |
6703.11 |
7862.24 |
NaN |
| 2012-01-01 - 2012-12-31 |
2181.35 |
3874.69 |
5226.86 |
6501.85 |
NaN |
NaN |
| 2013-01-01 - 2013-12-31 |
2179.85 |
3609.81 |
5227.75 |
NaN |
NaN |
NaN |
| 2014-01-01 - 2014-12-31 |
1830.85 |
3262.05 |
NaN |
NaN |
NaN |
NaN |
| 2015-01-01 - 2015-12-31 |
1912.17 |
NaN |
NaN |
NaN |
NaN |
NaN |
Step 4. Calculate cumulative transaction amounts
# Copy the df since they have the same structure
newcust_cmltv=Amount_cmltv.copy()
Get # new Customers for each year
#get # new customers for each year
newcust=group.groupby('Group').CustomerID.count()
newcust
Group
2010 172
2011 170
2012 163
2013 180
2014 155
2015 160
Name: CustomerID, dtype: int64
newcustomer table has the same structure with amount table instead of numbers
import numpy as np
for i in range(newcust_cmltv.shape[0]):
newcust_cmltv.iloc [i,]=[newcust.iloc[i]]*(6-i)+[np.NaN]*i
| Origin |
12 |
24 |
36 |
48 |
60 |
72 |
| 2010-01-01 - 2010-12-31 |
172.0 |
172.0 |
172.0 |
172.0 |
172.0 |
172.0 |
| 2011-01-01 - 2011-12-31 |
170.0 |
170.0 |
170.0 |
170.0 |
170.0 |
NaN |
| 2012-01-01 - 2012-12-31 |
163.0 |
163.0 |
163.0 |
163.0 |
NaN |
NaN |
| 2013-01-01 - 2013-12-31 |
180.0 |
180.0 |
180.0 |
NaN |
NaN |
NaN |
| 2014-01-01 - 2014-12-31 |
155.0 |
155.0 |
NaN |
NaN |
NaN |
NaN |
| 2015-01-01 - 2015-12-31 |
160.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
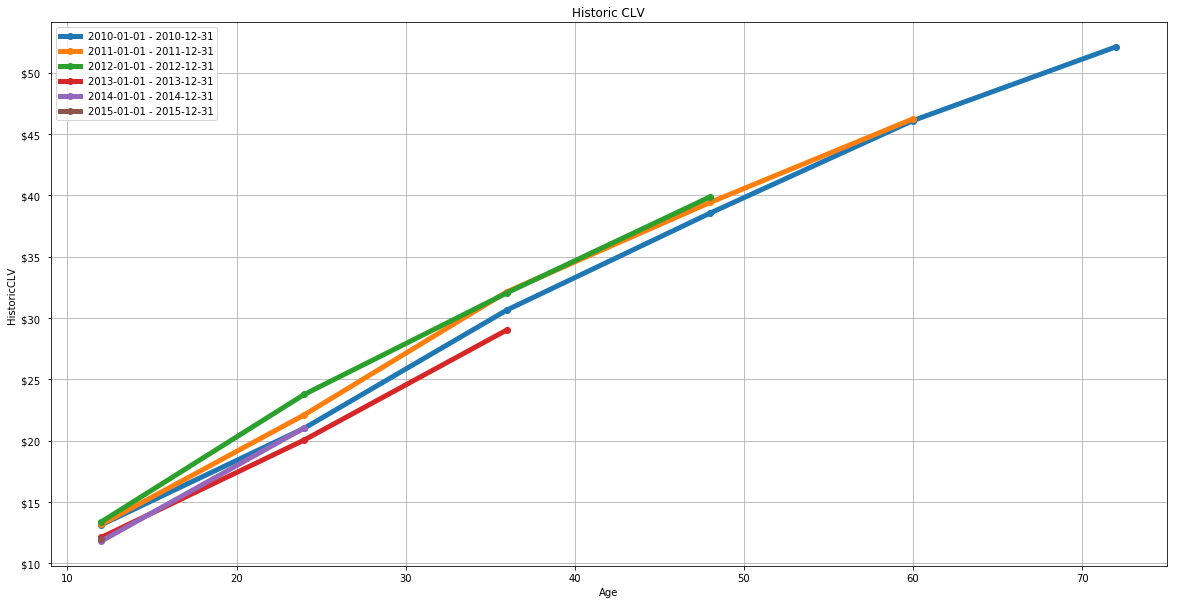
Step 6. Historic CLV
H_CLV=Amount_cmltv/newcust_cmltv
| Origin |
12 |
24 |
36 |
48 |
60 |
72 |
| 2010-01-01 - 2010-12-31 |
13.137616 |
21.016163 |
30.667500 |
38.560291 |
46.108663 |
52.119128 |
| 2011-01-01 - 2011-12-31 |
13.167412 |
22.105294 |
32.152882 |
39.430059 |
46.248471 |
NaN |
| 2012-01-01 - 2012-12-31 |
13.382515 |
23.771104 |
32.066626 |
39.888650 |
NaN |
NaN |
| 2013-01-01 - 2013-12-31 |
12.110278 |
20.054500 |
29.043056 |
NaN |
NaN |
NaN |
| 2014-01-01 - 2014-12-31 |
11.811935 |
21.045484 |
NaN |
NaN |
NaN |
NaN |
| 2015-01-01 - 2015-12-31 |
11.951062 |
NaN |
NaN |
NaN |
NaN |
NaN |
from matplotlib.ticker import FormatStrFormatter
plt.figure(figsize=(20,10))
plt.plot(H_CLV.T,linewidth=5,marker='o')
plt.title('Historic CLV')
plt.ylabel('HistoricCLV')
plt.xlabel('Age')
plt.legend(list(Amount_cmltv.index))
plt.gca().yaxis.set_major_formatter(FormatStrFormatter('$%d '))
plt.grid()
| Origin |
12 |
24 |
36 |
48 |
60 |
72 |
| 2010-01-01 - 2010-12-31 |
172.0 |
172.0 |
172.0 |
172.0 |
172.0 |
172.0 |
| 2011-01-01 - 2011-12-31 |
170.0 |
170.0 |
170.0 |
170.0 |
170.0 |
NaN |
| 2012-01-01 - 2012-12-31 |
163.0 |
163.0 |
163.0 |
163.0 |
NaN |
NaN |
| 2013-01-01 - 2013-12-31 |
180.0 |
180.0 |
180.0 |
NaN |
NaN |
NaN |
| 2014-01-01 - 2014-12-31 |
155.0 |
155.0 |
NaN |
NaN |
NaN |
NaN |
| 2015-01-01 - 2015-12-31 |
160.0 |
NaN |
NaN |
NaN |
NaN |
NaN |
| Origin |
12 |
24 |
36 |
48 |
60 |
72 |
| 2010-01-01 - 2010-12-31 |
13.137616 |
21.016163 |
30.667500 |
38.560291 |
46.108663 |
52.119128 |
| 2011-01-01 - 2011-12-31 |
13.167412 |
22.105294 |
32.152882 |
39.430059 |
46.248471 |
NaN |
| 2012-01-01 - 2012-12-31 |
13.382515 |
23.771104 |
32.066626 |
39.888650 |
NaN |
NaN |
| 2013-01-01 - 2013-12-31 |
12.110278 |
20.054500 |
29.043056 |
NaN |
NaN |
NaN |
| 2014-01-01 - 2014-12-31 |
11.811935 |
21.045484 |
NaN |
NaN |
NaN |
NaN |
| 2015-01-01 - 2015-12-31 |
11.951062 |
NaN |
NaN |
NaN |
NaN |
NaN |
newcust_cmltv.fillna(0)*H_CLV.fillna(0)
| Origin |
12 |
24 |
36 |
48 |
60 |
72 |
| 2010-01-01 - 2010-12-31 |
2259.67 |
3614.78 |
5274.81 |
6632.37 |
7930.69 |
8964.49 |
| 2011-01-01 - 2011-12-31 |
2238.46 |
3757.90 |
5465.99 |
6703.11 |
7862.24 |
0.00 |
| 2012-01-01 - 2012-12-31 |
2181.35 |
3874.69 |
5226.86 |
6501.85 |
0.00 |
0.00 |
| 2013-01-01 - 2013-12-31 |
2179.85 |
3609.81 |
5227.75 |
0.00 |
0.00 |
0.00 |
| 2014-01-01 - 2014-12-31 |
1830.85 |
3262.05 |
0.00 |
0.00 |
0.00 |
0.00 |
| 2015-01-01 - 2015-12-31 |
1912.17 |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
volume-weighted average of the Historic CLV for each group at each Age
newcust_cmltv.fillna(0).sum()
Origin
12 1000.0
24 840.0
36 685.0
48 505.0
60 342.0
72 172.0
dtype: float64
# Weighted average: sum(H_CLV*newcust_cmltv)/sum(newcust_cmltv)
singleCLV=pd.DataFrame(np.sum(newcust_cmltv.fillna(0)*H_CLV.fillna(0))/np.sum(newcust_cmltv)).reset_index()
singleCLV.columns= ['Age','HistoricCLV']
|
Age |
HistoricCLV |
| 0 |
12 |
12.602350 |
| 1 |
24 |
21.570512 |
| 2 |
36 |
30.942204 |
| 3 |
48 |
39.281842 |
| 4 |
60 |
46.178158 |
| 5 |
72 |
52.119128 |
Conclusion
Pandas is really strong to manipulate data. However, groupby function can be very confusing when it creates multi-index or index-dataframe. When we apply sum() or crosstab() later, it is easy to get trouble. Therefore, every step to generate a dataframe worths time to scrutinize.